Mutation testing is an advanced and effective strategy for verifying the robustness of our tests. This type of testing performs small modifications to the code, each one called a mutant. Each mutant is launched against our test suite. If our tests are solid, they will fail when a mutant is introduced. In such a case, the mutant will have been killed. Conversely, if no test fails, the mutant survives, suggesting that our tests do not cover all possible execution paths of our application.
Types of Mutation Testing
There are mainly three types of mutation testing:
- Statement Mutation. This type alters the code structure, such as omitting or reordering lines, to evaluate the detection of structural changes. For example, a = 1; b = 2; to b = 2;a = 1;.
- Value Mutation. The constant values within the code are modified. This variant tests the tests’ ability to handle changes in the data. For example, a = 1 to a = 2.
- Decision Mutation. It changes the logical conditions, challenging the tests to recognize variations in the execution flow. For example, a > 1 to a >= 1.
How to apply Mutation Testing?
Undoubtedly, the easiest way is by using libraries that provide everything needed to implement this type of testing at a very low cost. In my case, I have used Infection (PHP) and Stryker (JavaScript). I use Infection on a daily basis and it is the library I recommend if you use PHP. It allows disabling the types of mutations you want, integrating it with PHPUnit, etc. Also very useful is the HTML report it builds after each execution, facilitating the visualization of the results.
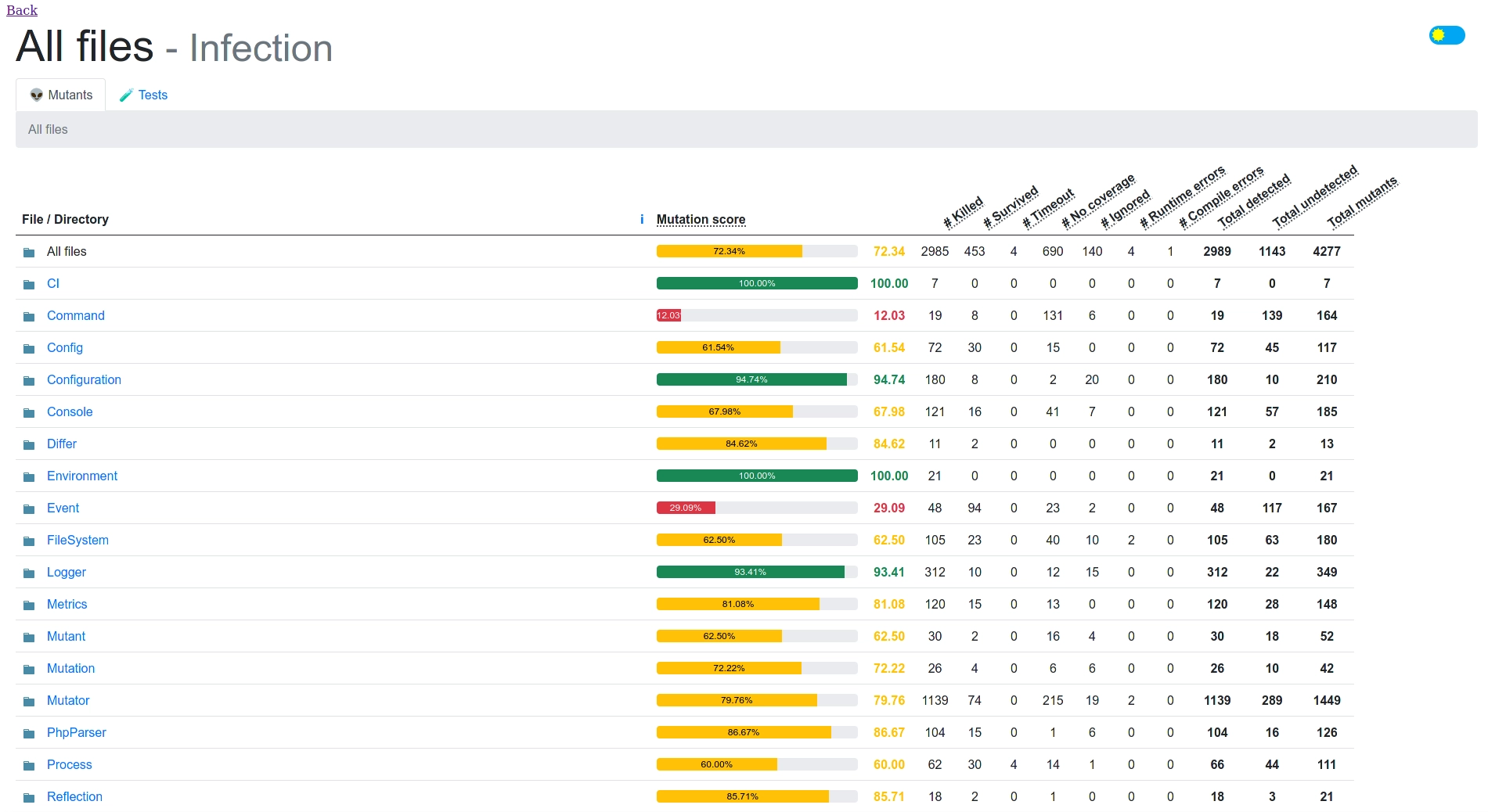
What problems do Mutation Tests introduce?
Most developers I know who have used this type of testing have mixed feelings. They like it because it helps to develop solid tests, but they hate it because sometimes it is frustrating.
Some mutants can be difficult to understand, so it may take time to comprehend why the mutant survives. This problem can be exacerbated if our tests are based on random data; it may be that no mutant appears in some executions while in others it does.
However, with experience, this cost is reduced. When I am implementing a use case, I already know, more or less, what tests I must implement so that there are no mutants. Why? Because I have already programmed similar use cases and have already suffered killing one by one all the mutants that appeared. Thus, there is always some mutant that escapes you, but when you have been implementing these tests for a while, the amount of time you have to dedicate to them each time is less.
When is it advisable to apply Mutation Testing?
In my opinion, mutation testing is an extremely valuable tool for improving the quality of our tests as long as we have a solid base of tests and high coverage. In fact, in my day-to-day, I do not pay attention to test coverage since it seems to me a vanity metric, but to the quantity of mutants.
Why? Because it is (relatively) easy for your tests to go through all the code, but it is really complex for your tests to go through all possible execution branches.
Furthermore, if your goal is to have no living mutants, you are forced to adopt good development practices. For example, mutants appear like mushrooms in classes with high cyclomatic complexity. This induces the development of classes/methods that do a single thing and in the simplest way possible.
However, if we do not have a good base of tests, my recommendation is simply to try to improve it. The metric in these cases is to increase coverage. I have already said that I consider it a vanity metric, but when there is nothing, anything that can make us improve serves. Of course, this is a task that can take a lot of time (and I will talk in another post about strategies to address these changes) but the most practical is to carry out a progressive increase in coverage. For example, the pipeline of a PR only allows you to merge if there is an increase of a X% in coverage. This forces developers to increase, even if by 0.01%, the coverage in each new development.
If we have a reasonable base of tests and want to introduce mutation testing, then the advisable thing is to deactivate most of the mutants and activate them little by little. We can then improve our tests and at the same time reduce the number of mutants. I also recommend this last step even if we have a large base of tests since if there is no previous experience with this type of tests, it is very likely that there are more mutants than lines of code.
Try it out!
I have created in this repository a proof of concept so that you can try firsthand how it works. Delete the test and try to kill all the mutants.